WarpBuild's Observability Architecture
How WarpBuild built a zero-maintenance observability system using S3, presigned URLs, and OpenTelemetry - achieving infinite scalability with minimal infrastructure.
Observability is critical for understanding CI/CD performance, but traditional observability stacks are complex, expensive, and require significant operational overhead. WarpBuild took a radically different approach: an S3-first architecture that eliminates maintenance burden while providing infinite scalability.
Key Benefits
- Zero maintenance: No databases, no clusters, no operational burden
- Infinite scalability: Built on S3's proven durability and scale
- Minimal infrastructure: Two simple components instead of complex observability stacks
- Cost-effective: Pay only for S3 storage and data transfer
This post walks through the architecture decisions that make this possible and why this approach works uniquely well for CI observability.
The Textbook Observability Stack
Most observability systems follow a familiar pattern:
This architecture requires:
- Multiple service tiers (collector, gateway, storage, query layer)
- Database clusters with replication and backups
- Query optimization and indexing strategies
- Monitoring for the monitoring system
- Capacity planning and scaling
- Multi-tenant support in each of the tiers
For general-purpose observability, this complexity is necessary. Since WarpBuild is not general purpose observability, it has unique characteristics that allow for a much simpler approach.
Not cargo-culting hardcore observability architecture, but building for the specific use case of CI/CD observability has huge advantages in our case.
WarpBuild's S3-First Architecture
High-Level Architecture
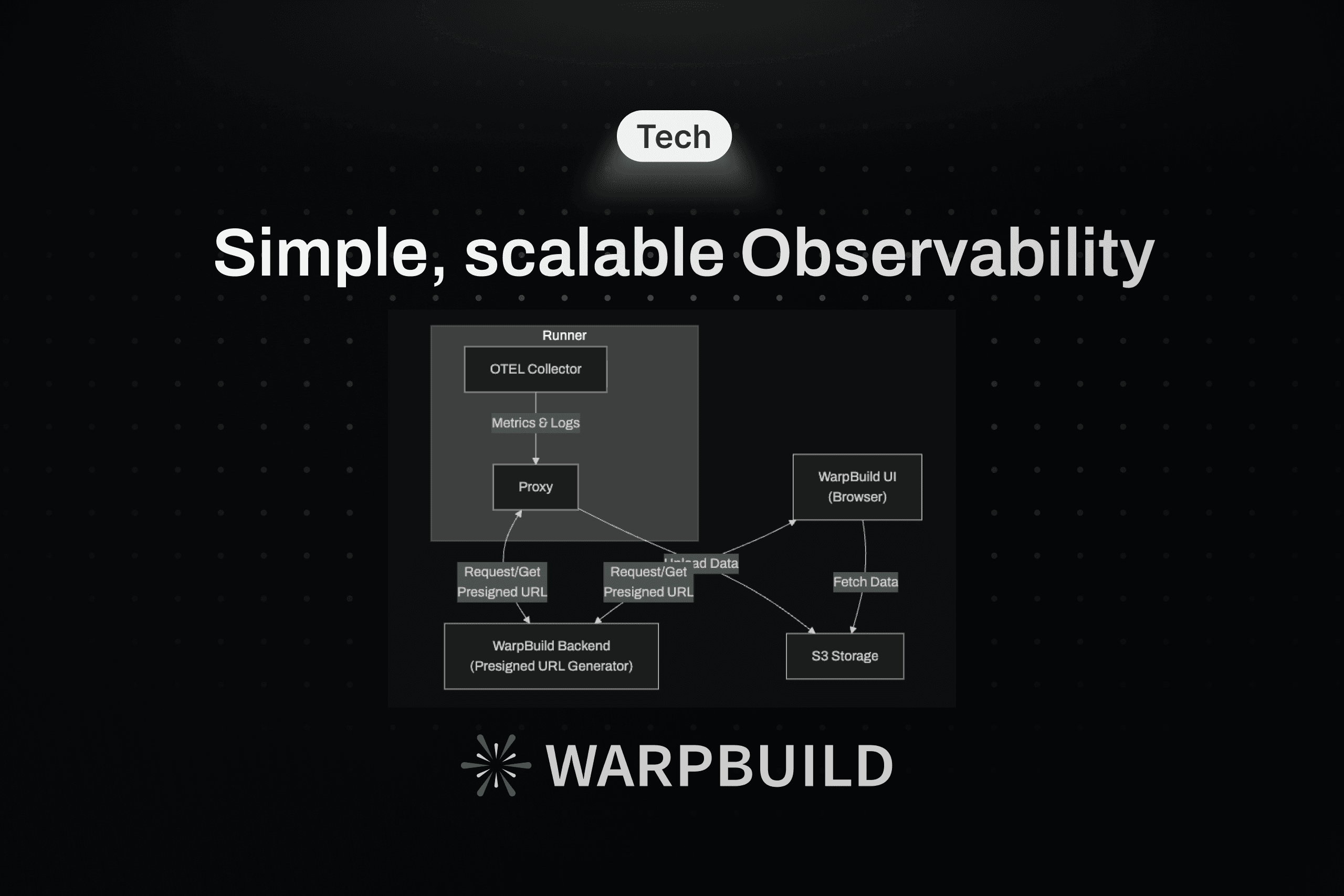
Here's the complete observability flow in WarpBuild:
WarpBuild's observability architecture has two simple paths: ingestion and retrieval.
Data Ingestion Path
When a job runs on a WarpBuild runner, metrics and logs flow directly to S3:
Key components:
-
OpenTelemetry Collector: Starts automatically when the runner boots, collecting system metrics (CPU, memory, disk, network) and logs.
-
Conditional Collection: When a GitHub Actions job is allocated, the system checks if observability is enabled. If disabled, the collector is killed immediately to save resources.
-
Proxy Service: A lightweight proxy running on the runner that handles authentication and presigned URL generation. This exists because OTEL collectors don't natively support S3 presigned URLs—they require long-lived credentials.
-
Direct S3 Upload: Using presigned URLs, data flows directly from the runner to S3 without passing through intermediate services.
Why a Proxy?
OpenTelemetry collectors are designed to work with credential-based authentication (IAM roles, access keys). Since WarpBuild uses presigned URLs for security and simplicity, the proxy translates between OTEL's credential expectations and S3's presigned URL model. The proxy is minimal and handles only URL generation and secure communication with the backend.
Data Retrieval Path
When a user views observability data in the WarpBuild UI, the architecture is even simpler:
The retrieval path has no intermediate query layer, no caching tier, no aggregation service. The browser fetches data directly from S3 and renders it. That's it.
Why This Architecture Works
This simplified architecture is possible because of several unique characteristics of CI/CD observability:
Display-Only Use Case
Unlike application monitoring where you need real-time alerting and complex queries, CI observability is primarily for human consumption. Developers want to see:
- What resources did my job use?
- When did the CPU spike?
- What errors appeared in the logs?
These are simple, single-job queries that don't require sophisticated query engines or real-time aggregation.
No Cross-Job Querying
Each CI job is isolated. Developers rarely need to query across multiple jobs simultaneously based on log contents or metric patterns.
When aggregate analysis is needed (e.g., "show me all jobs that failed with X error this week"), AWS Athena can query S3 data directly using SQL without building a dedicated query layer.
Small Data Volumes Per Job
CI jobs typically generate a few megabytes of metrics and logs. Even heavy jobs rarely exceed tens of megabytes. This means:
- S3's latency is acceptable (100-200ms to fetch a job's data)
- Transfers are throughput bound, not latency constrained
Zero Maintenance Infrastructure
By using S3 as the primary storage and query layer, WarpBuild eliminates:
- Database clusters that need monitoring and scaling
- Index management and optimization
- Backup and disaster recovery processes
- Software upgrades and security patches
S3 provides 99.999999999% (11 nines) durability and built-in versioning, replication, and lifecycle management.
Architecture Benefits
The entire observability system is two components:
- OTEL collector with S3 export (via proxy)
- Presigned URL generation in the backend
The most important benefit
The most important benefit is that we do not need to manage any infrastructure, while providing extremely fast data retrieval for end users as we do not have throughput bottlenecks with databases.
At 1 Million jobs/day, the data volume is ~1TB/day, which quickly gets out of control in databases. Besides, we do not need database features like aggregation, indexing, etc.
Traditional observability stacks cost many thousands of dollars per month for database clusters, monitoring infrastructure, not including engineering time.
With our architecture at 1 million jobs/day with 1MB data each, the total cost is ~$700/month instead of thousands - a 100x cost reduction with better reliability.
Trade-offs
This architecture isn't great for:
- Aggregate analysis of metrics (p50, p90, p99, deviation from the median, etc.)
- Metrics visualization (histogram, scatter plot, etc.)
However, this is easily achievable by layering on AWS Athena and other tools.
Conclusion
Context matters. The "textbook" observability stack is necessary for real-time monitoring and complex querying, but our requirements allow for radical simplification.
By leveraging S3's durability, scalability, and simplicity, WarpBuild delivers robust observability with:
- Zero maintenance burden
- Infinite scalability
- Two simple components instead of a complex stack, with no scalability concerns
This architectural decision embodies WarpBuild's philosophy: build for scale with minimal people. As the platform grows, the observability system requires no additional engineering effort - it just works.
Hat-tip
Our architecture is inspired by the rise of S3-first architectures in the industry including turbopuffer and others.
Learn More
- View job metrics and logs: WarpBuild Observability Dashboard
- Documentation: Observability Docs
- Get started: Quick Start Guide
Try WarpBuild
Experience zero-maintenance observability alongside the world's fastest CI runners. Get started in minutes: app.warpbuild.com
Call for developers
We are looking for developers who are interested in building the future of CI/CD. If you are interested in this, get in touch with us at [email protected]!
Last updated on